Title here
Summary here
As part of LANL's exploration of the CSM codebase, they replaced Etcd with PostgreSQL for BSS persistence and learned a lot about software boundaries along the way.
As part of LANL’s project to discover and boot a small cluster using components from Cray System Manager (CSM), we needed to deeply understand the existing Boot Script Service (BSS). We used BSS as an example service to make a substantive change to the software as shipped by HPE. We replaced the existing Etcd database with a PostgreSQL instance that was easier for us to manage.
We should point out that the Etcd implementation itself wasn’t problematic. We’ve seen it successfully used to boot hundreds of nodes without issue. Our goal was to assess the level of effort needed to identify internal boundaries in the CSM service and make changes without altering the fundamental behavior of the service.
Before we delve too deeply into the function of the BSS microservice, we should clarify a few things. For HPC systems like the Cray EX systems delivered by HPE, boot management is slightly different than you might be familiar with in your datacenter. First of all, the compute nodes are generally “stateless”. From one reboot to another, nothing is preserved. In fact, many HPC systems use compute nodes that lack internal disks. They boot from a network image and run entirely from RAM. BSS is a microservice for managing how the network filesystem is configured and delivered to a set of compute nodes. HPC administrators use API calls to BSS to pick the kernel and network boot images along with boot parameters. On a system with thousands of nodes that may each contain different hardware and network configurations, the combination of settings needed can be fairly cumbersome.
As a component of CSM, BSS stores the boot configuration of nodes. This information includes the URI of the kernel to boot, as well as an optional URI of an initrd (if the kernel expects one) and an optional string of kernel boot parameters. When a stateless node requests its DHCP configuration, the DHCP server directs the node to obtain a boot script from the BSS “bootscript” endpoint. That endpoint can differentiate between hosts based on hostname or MAC and generate an iPXE boot script that integrates the kernel/initrd URIs and any boot parameters. The iPXE bootloader, running on the compute node, can then HTTP GET the kernel and initrd specified in the script and boot them with any configured kernel parameters.
The way that BSS originally stored this data was via key-value storage. Etcd has a robust storage mechanism: it uses a quorum of nodes to decide what data changes and when this data should change, and it provides data redundancy in case a node (or its storage media) go down. This is great on an exascale system, but rather inconvenient on a smaller system, for example, a ten-node cluster. On a scale as small as this, we would rather have a lightweight storage backend like a PostgreSQL database. For this reason as well as others, the ability to use a PostgreSQL backend was added to BSS for smaller deployments.
Concepts in key-value storage do not translate well into concepts in relational databases. Instead of simply defining a key and storing a piece of data at that key, some foresight into the relationships between objects had to be established. It took four rounds to get a schema that made sense and could be implemented adequately. This is the schema that we came up with:
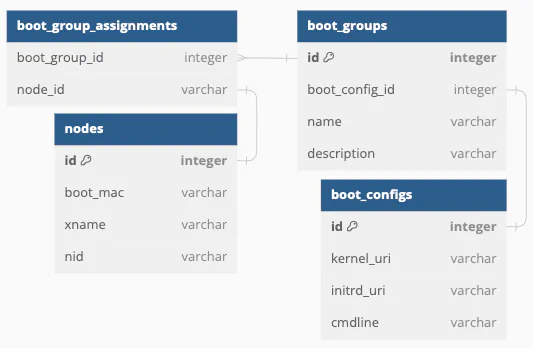
At the core, nodes (specified by boot MAC address, hostname, or node ID) are assigned a boot configuration, which consists of a kernel URI, an optional initrd URI, and optional kernel parameters.
BSS also supports named node groups. Rather than storing identical data for multiple nodes, a single name can be assigned to a boot configuration. Any nodes that are a member of the named group will share that boot configuration. Through interplay between the inventory system and BSS, grouping is stored as a feature of the inventory and used within BSS. In the interest of a speedy experiment, we decided to forgo the integration challenge of making changes to two services so grouping support is not part of our current fork. This highlights the one issue of working with CSM code: the APIs are not as cleanly separated by domain as we would like and exploring the grouping feature further will require some kind of architectural change.
The nodes and boot_configs tables were the obvious structures that were
needed first for the aforementioned node-boot-config relationship. The question
was then how to relate the two.
Since nodes could be members of a boot group, the boot_groups table made sense
to have as well. Plus, if multiple un-grouped nodes had the same boot
configuration, a single boot group (and corresponding boot configuration) whose
name was not specifically defined could be created for these nodes to share.
That way, many duplicate boot configurations need not be created in the
database. Therefore, boot groups serve the purpose of grouping nodes by boot
configuration, whether or not they are a member of a named group. Now, how
should nodes be assigned to boot configurations (or, more technically, a boot
group)?
Rather than have each node itself keep track of which boot group it is a part
of, a separate table that maps nodes to boot groups, the
boot_group_assignments table, was created to make joins easier and less
costly. This table maps node UUIDs to boot group UUIDs, so querying the nodes in
a boot group or querying the boot groups (and therefore boot configurations) for
one or more nodes is just a matter of joining the tables.
When BSS receives a request to produce an iPXE boot script for a node, it first checks the State Management Database (SMD) for the node’s existence, since the node has to have been discovered by Magellan and be populated in SMD in order for it to have a boot configuration. It turns out that it was not possible to manually add nodes to SMD without using discovery for testing BSS, and so SMD was modified to be able to do so.
Once the node has been verified to exist, an iPXE boot script is generated using the node’s boot MAC address and kernel URI, as well as the initrd URI and kernel parameters if they were specified. If the node does not exist, a generic, failover iPXE boot script is generated.
If, for example, a node is added like so (assuming this node exists in SMD with
xname x0c0s1b0):
{
"macs": ["02:0b:b8:00:30:00"],
"kernel": "https://example.org/kernel",
"initrd": "https://example.org/initrd",
"params": "console=tty0 console=ttyS0,115200n8"
}then a boot script generated could look like (ignoring cloud-init):
#!ipxe
kernel --name kernel https://example.org/kernel initrd=initrd console=tty0 console=ttyS0,115200n8 xname=x0c0s1b0 ds=nocloud-net;s=localhost/ || goto boot_retry
initrd --name initrd https://example.org/initrd || goto boot_retry
boot || goto boot_retry
:boot_retry
sleep 30
chain https://api-gw-service-nmn.local/apis/bss/boot/v1/bootscript?mac=02:0b:b8:00:30:00&retry=1The boot script will try to boot the kernel specified at the kernel URI, passing in the kernel parameters, and will try to use the initrd at the initrd URI, if passed. If any of these fail, it will fail over to the failover DHCP server and get that boot script.
If the node does not exist in SMD, the boot script generated will look something like the below, going straight to the failover boot script:
#!ipxe
sleep 10
chain https://api-gw-service-nmn.local/apis/bss/boot/v1/bootscript?mac=02:0b:b8:00:30:00&arch=${buildarch}&ts=1696373833While Etcd is a strong and robust storage backend, there are use cases where a smaller, less complex storage mechanism would suit better. With open source software like Ochami that is meant to be able to run on heterogeneous architectures and hardware, this addition to BSS will allow it to meet these diversity requirements. In the future, we would like to consider ways of making BSS function even better as a standalone boot script service with more composable storage options.
Ready to try OpenCHAMI?